With the announcement of HANA*, some customers, analysts and others have raised the question on how HANA relates to BW with a few of them even adding their own, home made answer in the sense that they speculate that HANA would succeed BW. In this blog, I like to throw in some food for thought on this.
Currently, HANA's predominant value propositions are
- extremely good performance for any type of workload
- a real-time replication mechanism between an operational system (like SAP ERP) and HANA
Let's match those for a moment with the original motivation for
building up a decision-support system (DSS) or data warehouse (DW). In the 1990s, a typical list of arguments in favour of such a system looked like this:
- Take load off operational systems.
- Provide data models that are more suitable and efficient for analysis and reporting.
- Integrate and harmonize various data sources.
- Historize - store a longer history of data (e.g. for compliance reasons), thereby relieving OLTPs from that task and the related data volumes.
- Perform data quality mechanisms.
- Secure OLTPs from unauthorized access.
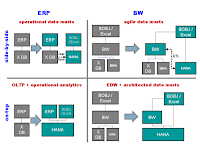
Installing a DW is typically motivated by a subset or all of those reasons. There is a particular sweet spot in that area, namely a DW (e.g. an SAP BW) set up for reasons 1. and 2., but with all the other arguments not being relevant as it is connected to basically one** operational system (like SAP ERP). Here, no data has to be integrated and harmonized, meaning that the "T-portion" in ETL or ELT is void and thus that we are down to extraction-load (EL) which, in turn, is ideally done real-time. So value proposition ii. comes along very handy. Critics will argue that such systems are no real data warehouses ... and I agree. But this is merely academic as such systems do exist and are a fact. So, in summary, there is a good case for a certain subset of "data warehouses" (or reporting systems) that can be now built based on HANA with i. and ii. as excelling properties - see the top left scenario in figure 1 below.
Now, will this replace some BWs? Yes, certainly. In the light of HANA, a BW with a 1:1 connection to an ERP might not be the best choice anymore. However, will this make BW obsolete in general? No, of course not. As indicated above: there is a huge case out there for data warehouses that integrate data from many heterogenous sources. Even if those sources are all SAP - e.g. a system landscape of multiple unharmonized ERPs, e.g. originating from regional structures, mergers and acquisitions - then this still requires conceptual layers that integrate, harmonize and consolidate huge volumes of data in a controlled fashion. See Jürgen Haupt's blog on LSA for a more comprehensive discussion of such an approach. I sometimes compare the data delivered to a data warehouse with timber delivered to a furniture factory: it is raw, basic material that needs to get refined in various stages depending on the type of furniture you want to produce - shelves might require less steps (i.e. "layers") than a cupboard.
Finally, I believe that there is an excellent case for building a BW on top of HANA, i.e. to combine both - see the bottom right scenario in the figure below. HANA can be seen as an evolution of BWA and, as such, this combination has already proven to be extremely successful: BW 7.0 and BWA 7.0 have been in the market for about 5 years, BW 7.30 and BWA 7.20 have pushed the topic even further albeit mainly focusing on the analytic layer of BW (in contrast to the DW layer). When you continue this line of thought and when you assume that HANA is not only BWA but also able to comply with primary storage requirements (ACID etc.) then the huge potential opens up to support, for example,
- integrated planning (BW-IP): atomic planning operators (used in planning functions) can be implemented natively inside HANA, thereby benefitting from the scalability and performance as seen with BWA and OLAP and also from avoiding to transport huge volumes of data from a DB server to an application server,
- data store objects (DSOs): one can think of implementing such an object natively (maybe as a special type of table) in HANA, thereby accelerating performance critical operations such as the data activation.
This is just a flavour of what is possible. So, overall, there is 4 potential and interesting HANA-based scenarios that I see and that are summarized in figure 1. I believe that HANA is great technology that will only come to shine if the apps exploit it properly. SAP, as the business application company, has a huge opportunity to create those apps. BW (as a DW app) is one example which has started quite some time ago on this path. So the question on the BW-HANA relationship
has an obvious answer.
*
High Performance
ANalytic
Appliance
** The case remains valid even if there are a few supporting data feeds, e.g. from small complementary sources.


